Thinking in Pipelines
Each chapter is being updated to match the latest version of the print book, available from Amazon and No Starch Press. There may be some inconsistencies in links or minor content differences until this page is fully migrated.
Understanding the concept of pipelines in the shell, as well as how input and output work for command line programs is critical to be able to use the shell effectively.
In this chapter, we'll look at the ways programs handle input and output, then we'll look at how we can chain multiple commands together with pipelines. We'll also look at some really common ways to use pipelines which should hopefully make your life easier!
When you understand these concepts, it will open up a new world in terms of what you can do with in the shell. We'll briefly touch on the 'The Unix Philosophy', which is a concept which allows us to perform highly complex tasks by composing together small, simple components.
Input and Output
Many of the programs we have seen so far follow a very similar pattern:

In fact, when you get down to the details, there are very few programs which don't do something like this! As a more concrete example, we can look at the sort program - which sorts the input in alphabetic order:
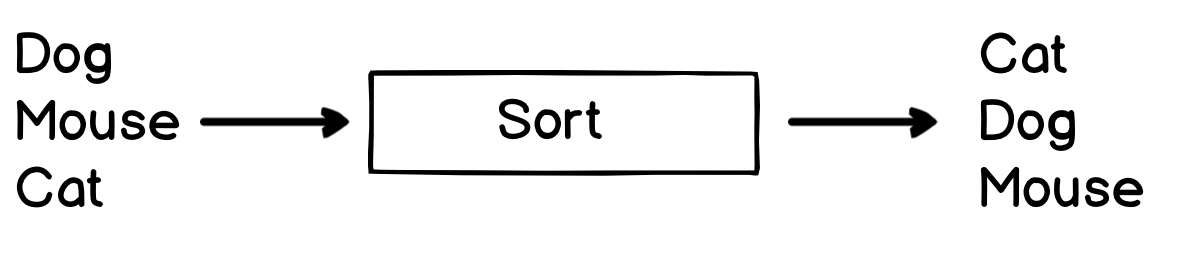
We can easily see this in action by just running sort in a shell. Start the sort program, enter some text, then press Ctrl+D. Ctrl+D (which is normally written as ^D is a special control character which means 'end of transmission' - in this case we use it to tell sort we've finished writing text. If you were to use ^C (which is the interrupt command) it would closes the sort program instead).
$ sort
Dogs
chase
cats
and
cats
chase
mice
Once you've entered the text you want to sort, hit ^D and you'll see the sorted output:
Dogs
and
cats
cats
chase
chase
mice
So by default, the sort command is reading input from the keyboard (until we send it a special message saying we're done), then writing the output to the terminal.
In fact, sort is using two special files - stdin and stdout - but what does this mean?
Standard Input, Output and Error
Every program has access to three 'special' files, stdin, stdout and stderr:
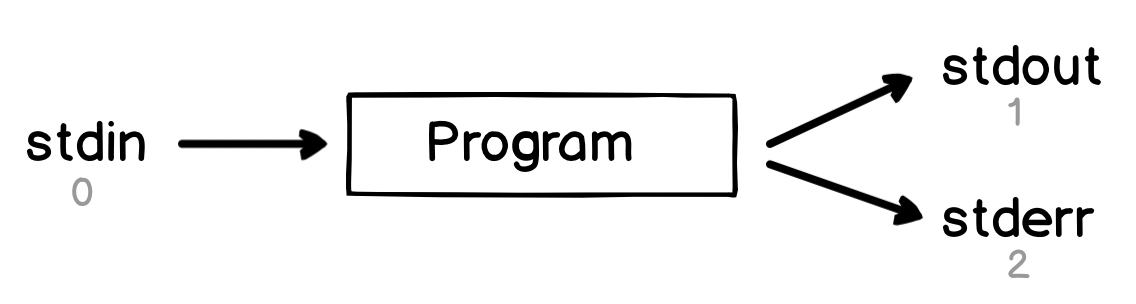
stdinis short for 'standard input' - it's where many programs read their input fromstdoutis short for 'standard output' - it's where many programs write their output tostderris short for 'standard error' - it's where some programs write error messages to
Why do I say 'many' and 'some'? Well the reason is that while this is convention, it is not adhered to universally. Anyone who writes a program is free to choose how they read input and write output, so some programs might not follow these conventions. In Chapter 29 we'll look at how to write tools which follow these conventions, as well as others which are useful.
Each of these files has a special number which is shown in grey in the diagram. This is known as the file descriptor and we'll see it later on. Each of these files also has a special location in the system which you can access directly - you can see these files by running ls -al /dev/std*:
$ ls -al /dev/std*
lr-xr-xr-x 1 root wheel 0 Jan 1 1970 /dev/stderr -> fd/2
lr-xr-xr-x 1 root wheel 0 Jan 1 1970 /dev/stdin -> fd/0
lr-xr-xr-x 1 root wheel 0 Jan 1 1970 /dev/stdout -> fd/1
If you are not familiar with ls (the list directory contents command) then check Chapter 2 - Navigating Your System. The first part of the output isn't too important - but we can see we have three files in the special /dev/ (short for device folder). We can also see the associated file descriptors.
As an aside - this is a really fundamental thing we'll see again and again in Unix and Linux - almost everything can be represented as a file. This is a core concept and one we'll touch on regularly.
When you are running programs in a shell, the shell attaches your keyboard to the program's standard input1, and attaches the standard output and standard error to the terminal display:
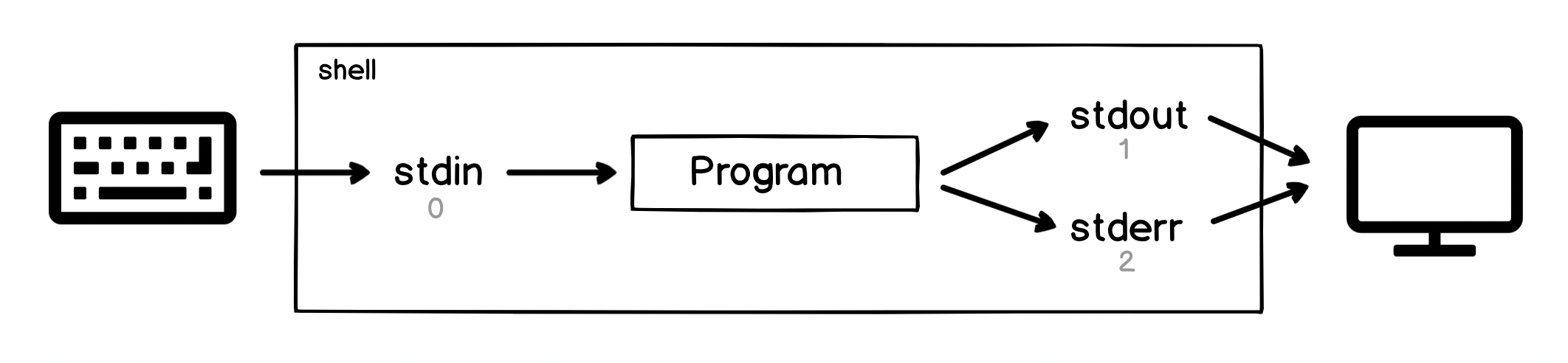
This means when we're in a shell, we can type on the keyboard, which goes to the input of the program and then as the program outputs information and errors they show up on the screen.
We can already see the beginnings of a pipeline here. There's a clear flow of data from the keyboard, through the stdin file, through the program, then through the output files, then to the display.
Looking at some real programs in action will hopefully make this clearer!
A Pipeline in Action
Do you remember the cat command? It's the one which writes the contents of a file to the screen. For example:
$ cat ~/effective-shell/text/simpsons-characters.txt
Artie Ziff
Kirk Van Houten
Timothy Lovejoy
Artie Ziff
Nick Riviera
Seymore Skinner
Hank Scorpio
Timothy Lovejoy
John Frink
Cletus Spuckler
Ruth Powers
Artie Ziff
Agnes Skinner
Helen Lovejoy
We saw in Chapter 4 - Becoming a Clipboard Gymnast that we could pipe the output of this command into the sort command to order it and then into the uniq command to remove duplicates, like this:
$ cat ~/effective-shell/text/simpsons-characters.txt | sort | uniq
Agnes Skinner
Artie Ziff
Cletus Spuckler
Hank Scorpio
Helen Lovejoy
John Frink
Kirk Van Houten
Nick Riviera
Ruth Powers
Seymore Skinner
Timothy Lovejoy
The pipe operator (which is the vertical pipe symbol or |) has a very specific meaning in the shell - it attaches the stdout of the first program to the stdin of the second. This means we can now visualise the entire pipeline and see exactly what is going on:

That's it! If you can follow what is going on here then you have the key information you need to know to understand how pipelines work. The pipe operator just connects the output of one program to the input of another. A pipeline is just a set of connected programs. Easy!
We could do the same thing by writing the output of each step as a file, then reading that file with the next step, but that would mean we'd have a lot of intermediate files to clean up (and if we're processing a big file, it also uses a lot of space). Pipelines let us create complex sequences of operations which work well even on very large files.
Now we'll look at stdin, stdout and stderr in a little more detail. We'll be seeing these special streams a lot as we go through the book. Knowing more about them is really going to help you when working in the shell or with Linux-like systems.
Common Patterns - Standard Input
Let's have a quick look at some of the common things we might see as sources of inputs for other programs. Each one illustrates an interesting point about how the shell or the standard input stream works.
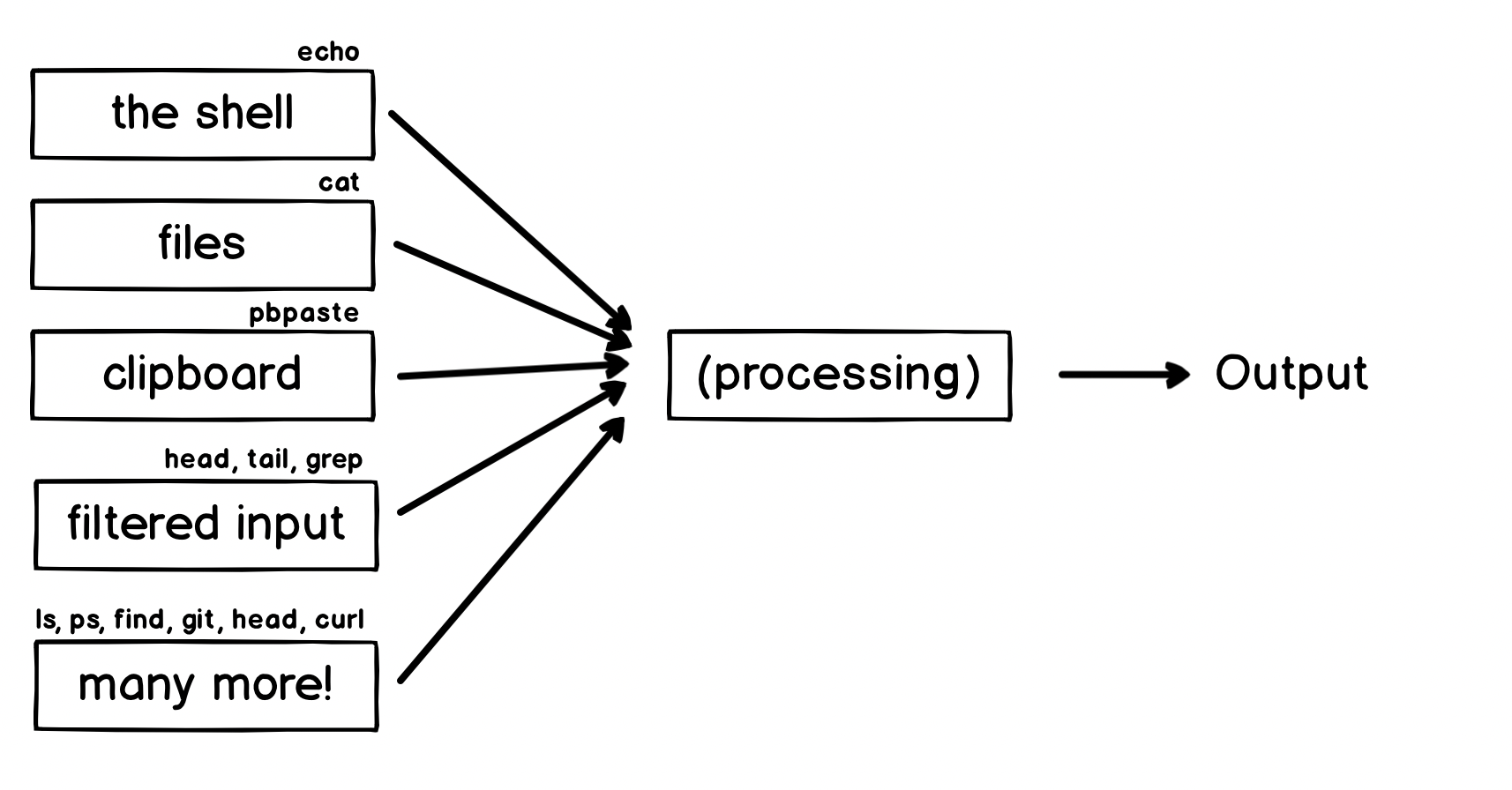
This list is by no means exhaustive, in fact with a bit of tinkering you can make almost anything the input to anything else, but let's check each example.
These examples will use some new programs to transform the output - don't worry about the details of them, each will be described as we go through the book!
The Shell
You might just use code in the shell as input, for example:
$ echo "I am in the $PWD folder" | sed 's/folder/directory/'
I am in the /Users/dwmkerr/repos/github/dwmkerr/effective-shell directory
Here we've just used echo to write out message including a variable and then used the sed (stream editor) program to replace the word folder with directory. We'll get a lot of practice with sed as we go through this book!
Files
We've already seen a few examples of using cat to write a file to stdout.
A lot of the time we don't need to use cat many programs accept the path of a file as a parameter, meaning we can just tell the program to open the file directly. For example, we could count the number of lines in a file like this:
$ cat ~/effective-shell/text/simpsons-characters.txt | wc -l
14
Or more simply, like this:
$ wc -l ~/effective-shell/text/simpsons-characters.txt
14 /Users/dwmkerr/effective-shell/text/simpsons-characters.txt
In this case, we've passed the file path as an argument to the wc (word, line, character and byte count) program. But be aware - not all programs use the same convention or parameter names!
Now here's a cool trick. Type rev < /dev/stdin, then enter some text and hit ^D or ^C when done. You should see something like this:
$ rev < /dev/stdin
Red Rum
muR deR
What's going on here? Remember we mentioned that stdin is a special stream which represents input and that it lives at /dev/stdin? This little trick uses redirection to redirect the stdin file to the rev (reverse) command.
The < operator redirects the standard input of a program to come from the given file. We could also have written cat /dev/stdin | rev. Or just enter rev and type in the input we want to reverse!
The Clipboard
In Chapter 4 - Becoming a Clipboard Gymnast we saw a trick to remove formatting from text in the clipboard. Here's a similar trick to reverse the contents of the clipboard:
$ pbpaste | rev | pbcopy
This pipeline pastes the contents of the clipboard to stdout, which is piped to rev (reversing the text) and then pipes the output to pbcopy, which copies the results to the clipboard2.
Filtered Input
This is a trick a friend shared with me. He works with data scientists and whenever he shows them this command they love it!
$ head -n 100 100GBFile.csv > 100linefile.csv
The head (display first lines of a file) command in this case just grabs the first 100 lines of a file and puts it straight into a smaller, more manageable file. We'll see what the > symbol (the redirection symbol) means in the section lower down on Standard Output.
You can also use tail in the same way to get the last lines from a file. And if you are a more advanced user, you might use something like this:
$ grep -C 5 error /var/log/mylogfile.txt | less
We'll see all of these commands as we go through the book, but this very cool trick uses the grep (file pattern searcher) command to search for the text error in the file /var/log/mylogfile.txt, shows five lines of context (-C 5), which are the lines before and after the match, then puts the result into your pager! We'll see the pager just below. We'll do a lot of grep-ing as we go through the book so don't worry if this looks a little confusing for now.
Many More!
We've only scratched the surface - almost any program will write to the standard output, meaning it can be the input for any pipeline you can imagine!
Common Patterns - Standard Output
Now let's look at some of the things we can do with the standard output:
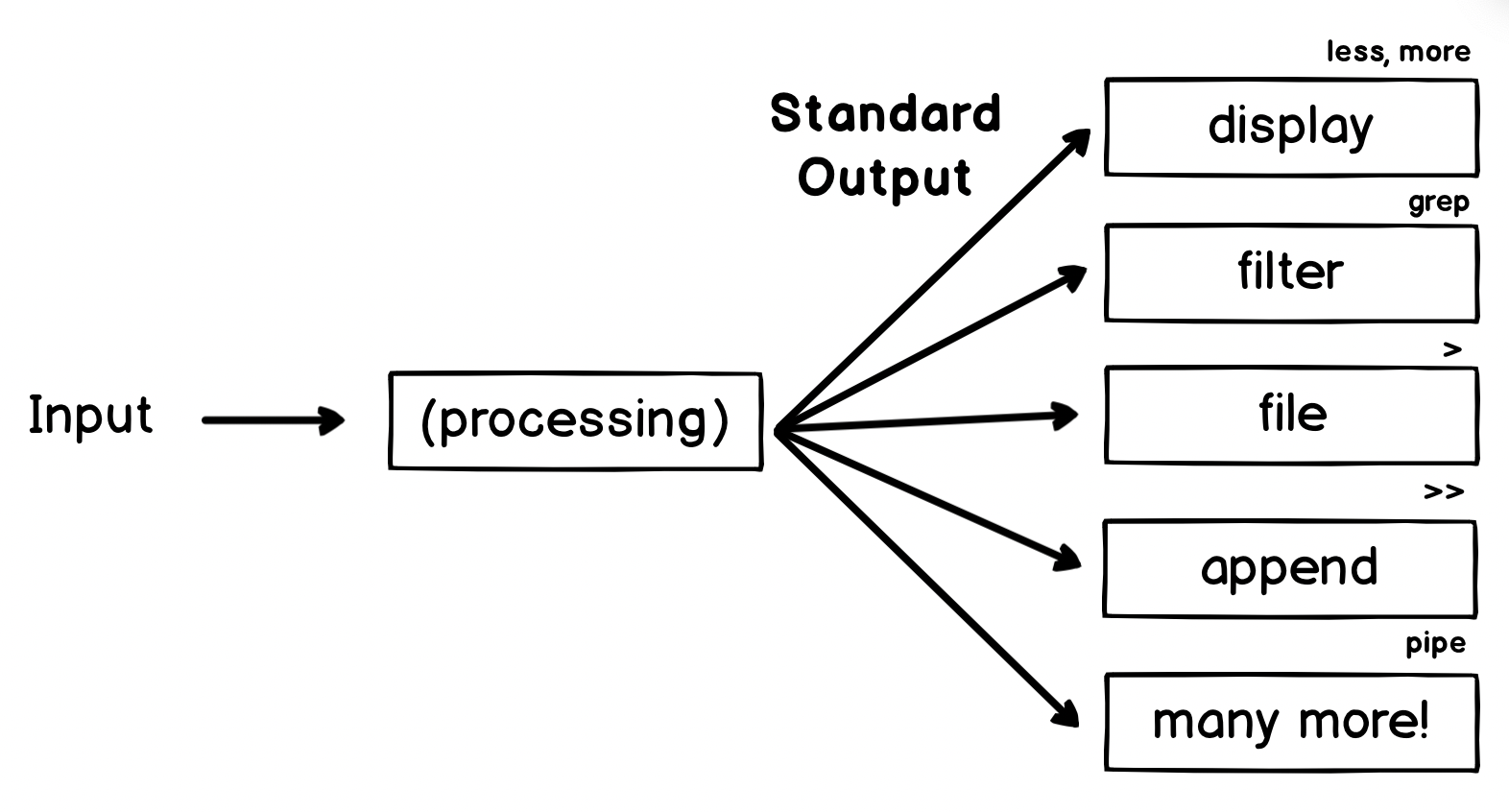
Some of these outputs are things we've seen before, but let's do a quick revision.
Display
This is what we've been doing a lot of so far. When you are working with the shell interactively this makes a lot of sense.
If you have jobs which run in the background (or on a timer, such as backup jobs which run nightly), you might not actually have a terminal attached to the program to see the output, in which case you'll likely write to a file.
What about if you have a lot of output? It can be quite inconvenient to have to scroll through the terminal (or impossible, depending on the system you are on). In this case use a pager. A pager is a program which makes it possible to interactively page through output in the shell, scrolling up and down, searching and so on.
Try this out as an example:
ls /usr/bin /usr/local/bin /usr/sbin | less
You'll see something like this:
This long list of files would be hard to search through if it was printed directly to the shell, but in the pager we can use the d and u keys to go down and up, or the / and ? keys to search forwards or backwards.
To quit the pager and get back to your shell, use the q key. This is a useful command to know: lots of tools will show their output in a pager without asking you, and pressing q will generally get you out of them.
Piping into your pager is a really useful trick - you can read more about pagers in Chapter 5 - Getting Help.
File
The shell has a built in operator which will pipe the standard output of a program and write it to a file. It is the > or redirection operator:
$ echo "Here's some data" > some_file.txt
It's as easy as that! Note that this will overwrite anything already in the file.
Append
What if you don't want to overwrite a file, but instead just add a new line? The >> or append redirection operator:
$ echo "Tuesday was good" >> diary.txt
$ echo "Wednesday was better!" >> diary.txt
$ echo "Thursday suuucks" >> diary.txt
$ cat diary.txt
Tuesday was good
Wednesday was better!
Thursday suuucks
This example writes each line in turn to the diary.txt file, appending the text to the end of the file (and creating it if it doesn't already exist).
Appending to a file is extremely useful for circumstances where you might want to build or update a log of events over time.
Pipe
This is what we've spent most of this chapter looking at - to simply pipe the standard output to the standard input of another program!
In this case, the output of our program becomes the input of the next one in the pipeline.
Common Patterns - Standard Error
We haven't actually seen stderr in action yet. Let's see how it works.
$ mkdir ~/effective-shell/new-folder
$ mkdir ~/effective-shell/new-folder
mkdir: /home/dwmkerr/effective-shell/new-folder: File exists
In the first call to mkdir, the folder is created successfully. In the second call, we get an error. Now let's try and use this output and make it louder - making all of the text uppercase.
There are lots of ways to make text uppercase in the shell, let's use the tr (translate characters) program. Here's an example of how it works:
$ echo 'Be quiet, this is a library!' | tr '[:lower:]' '[:upper:]'
BE QUIET, THIS IS A LIBRARY!
Now let's use it to shout out our error message:
$ mkdir ~/effective-shell/new-folder | tr '[:lower:]' '[:upper:]'
mkdir: /home/dwmkerr/effective-shell/new-folder: File exists
In this case the output has not been made uppercase. What's going on?
To understand, let's quickly review the three streams:
When we are in the shell, the shell automatically writes the stderr stream to the screen. But the shell's pipe operator pipes stdout only - it is not piping our error output. And the mkdir command is writing this error message to stderr.
The command we ran before:
mkdir ~/effective-shell/new-folder | tr '[:lower:]' '[:upper:]'
Actually looks like this:
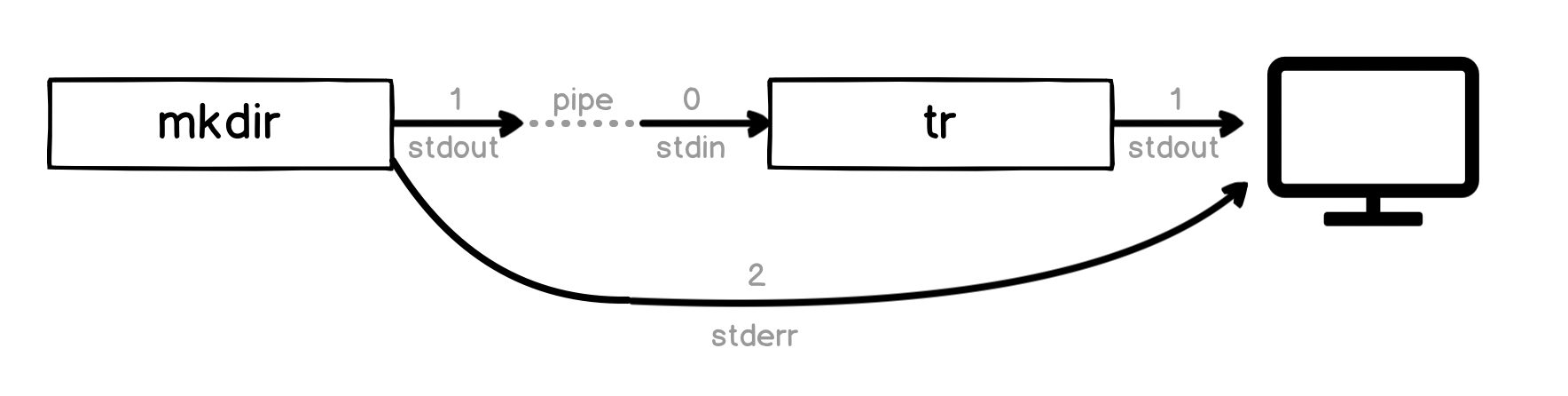
The pipe has piped the standard output to the tr program. But there is no standard output - the error message was written to standard error instead. The shell has still written it to the screen for us, but has not piped it to the tr program.
So how do we deal with stderr? Here are some common options:
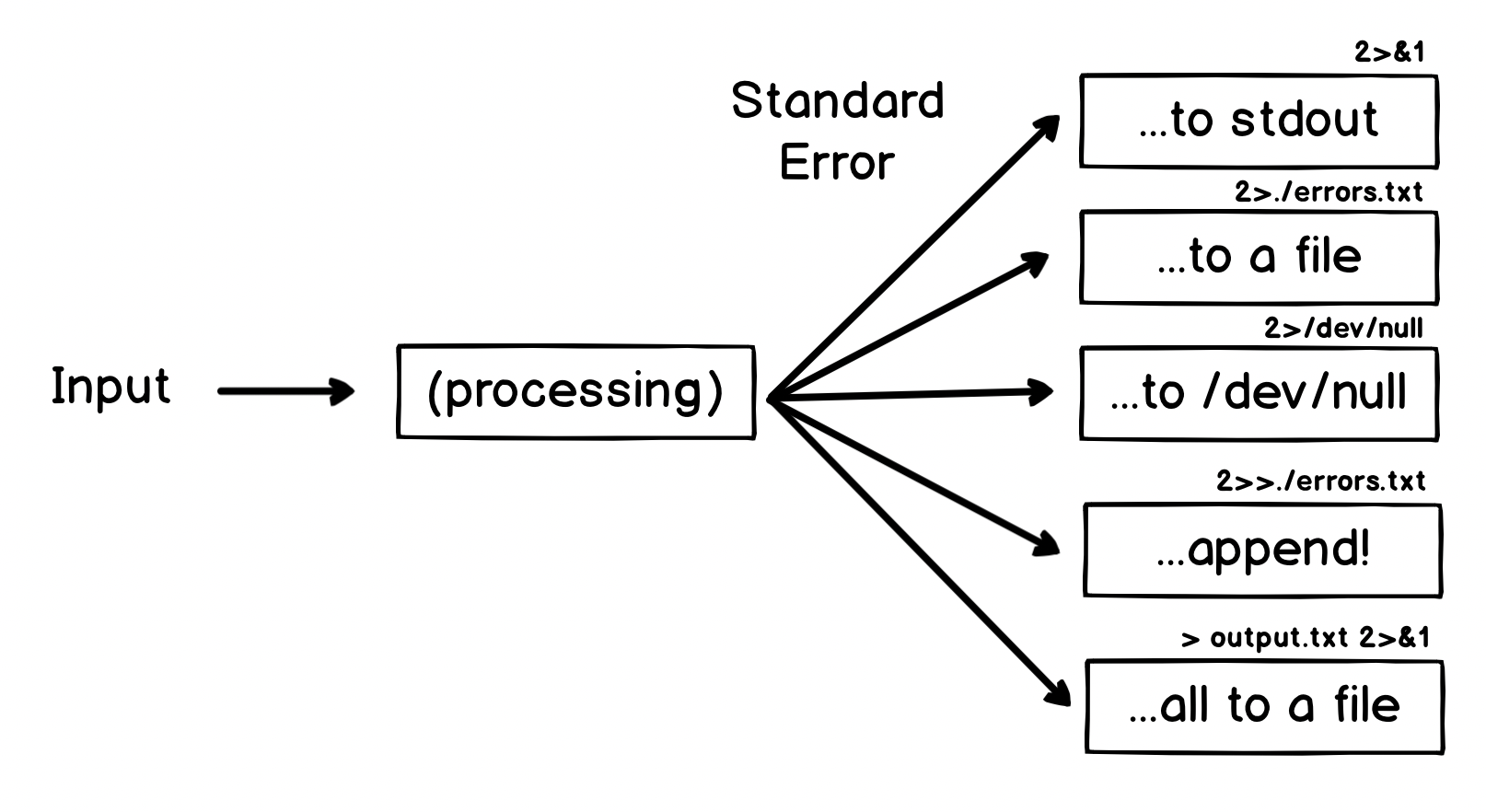
Now this might be the ah-ha! moment if you have done some shell scripting before - some of these obscure sequences like 2>&1 might look familiar (even if it is just the thing you know you always have to Google to get right!).
Let's take a quick look at some of these options.
To Standard Output
If we want to be able to pipe the error message to another command, we can use another redirection trick - we can redirect stderr to stdout.
The characters 2>&1 look really obscure - let's break it down:
- Take the file with descriptor
2- which is standard error - Redirect it with the redirect symbol
>- we saw this in the earlier section - Redirect it into the file with descriptor (
&)1- which is standard output
Remember, there are three 'magic' files each process has access to:
stdin, the standard input, which has the file descriptor0stdout, the standard output, which has the file descriptor1stderr, the standard error, which has the file descriptor2
File descriptors are just numbers the operating system uses to keep track of files. When a program opens a 'normal' file, it'll get a new file descriptor. Here's a little example:
python <<EOF
import os
for r in range(3): print(os.open('/dev/random', os.O_RDONLY))
EOF
This code uses redirection (see how useful it is?) to pipe a small Python script into the Python program, which writes the results to stdout. You will probably see the following output:
3
4
5
It doesn't really matter whether you know Python or not (and there weird looking EOF is a heredoc which we have a whole chapter on later). The script is just a way of showing the file descriptors that the operating system gives me when I try to open three files (each time I open the same file, the magic /dev/random file which just contains random data).
The interesting thing is that the descriptors in my program start from 3 and go upwards - that's because 0, 1 and 2 are already in use, for stdin, stdout and stderr!
So to make our error message go through the tr command, we can redirect stderr to stdout, which means the error message will go to stdout and then be piped to tr:
$ mkdir ~/effective-shell/new-folder 2>&1 | tr '[:lower:]' '[:upper:]'
MKDIR: /HOME/DWMKERR/PLAYGROUND/NEW-FOLDER: FILE EXISTS
Visually, what is happening is this:
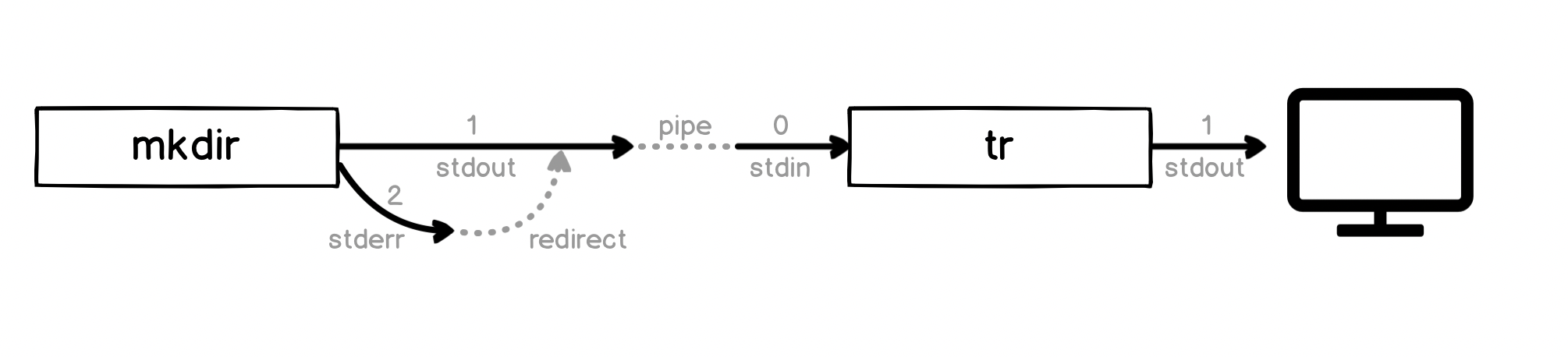
If you can wrap your head around this, the other options we showed for stderr might start to make a little more sense.
A nice trick to remember the slightly obscure ampersand & which references a file descriptor - if you were to write this:
cat some-file-that-might-not-exist 2>1
What would happen is that the shell would write stderr to a new file with the name 1! Why don't we need an ampersand before the > symbol, only for the file descriptor afterwards? This is just because the shell only supports redirecting file descriptors, so an additional ampersand would be superfluous.
To a File
Before, we redirected to &2, which is 'the file with descriptor 2. We can also use a similar trick to redirect to any arbitrary file:
mkdir ~/effective-shell/new-folder 2>./errors.txt
This command just redirects all of the errors (remember, 2 is stderr) to a file called ./errors.txt.
This is quite a common trick - run the program, but log the errors to a file for later review.
To Nowhere
What if we just don't want to see the errors at all? Well there's a special file called /dev/null which we can use for this. When we write to this file, the operating system just discards the input. In fact, it exists for just this kind of purpose!
mkdir ~/effective-shell/new-folder 2>/dev/null
This just redirects all errors to the black hole of /dev/null - we won't see them on the screen or anywhere else. This is a common way to 'silence' errors3 in shell commands.
Notice how we're starting to see patterns? This is just redirection, the same tricks we saw for stdout, but we're explicitly redirecting stderr (file descriptor 2). If we don't tell the shell what to redirect, it assumes stdout by default.
So if we can redirect, can we append too?
Append
Yes! Just like we did with stdout, there's nothing stopping us appending to a file:
mkdir ~/effective-shell/new-folder 2>>./all-errors.log
Just like before, we use >> which means append (rather than overwrite or create).
All to a File
This is a really important subtlety. If you want to write both stdout and stderr to a file, you might try this:
ls /usr/bin /nothing 2>&1 > all-output.txt
If you run this command, you'll get stdout written to all-output.txt, but the error message cannot access '/nothing' is written to the screen, not the file. Why is this?
Bash (and most bash-like shells) process redirections from left to right, and when we redirect we duplicate the source. So breaking this down:
2>&1- duplicate file descriptor2(stderr) and write it to1- which is currently the terminal!> all-output.txt- duplicate file descriptor1(stdout) and write it to a file calledall-output.txt
To write everything to the file, try do this:
ls /usr/bin /nothing > all-output.txt 2>&1
This will work. Breaking it down:
- Redirect
stdoutto the fileall-output.txt - Now redirect
stderrtostdout- which by this point has already been redirected to a file
This can be tough to remember so it's worth trying it out4. There are many variations you can play with and we'll see more as we go through the book.
One Last Trick - The T Pipe
This is a long chapter, but I can't talk about pipelines without briefly mentioning the T pipe. Check out this command:
cat ~/effective-shell/text/simpsons-characters.txt | sort | tee sorted.txt | uniq | grep '^A'
This command sorts the list of Simpsons characters, removes duplicates and filters down to ones which start with the letter A. And it has the tee command in the middle. What does this do?
Well the tee command is like a T-pipe in plumbing - it lets the stream of data go in two directions! The sorted.txt file contains the sets of characters after the sort operation, but before the unique and filter operation. Visually, it does this:
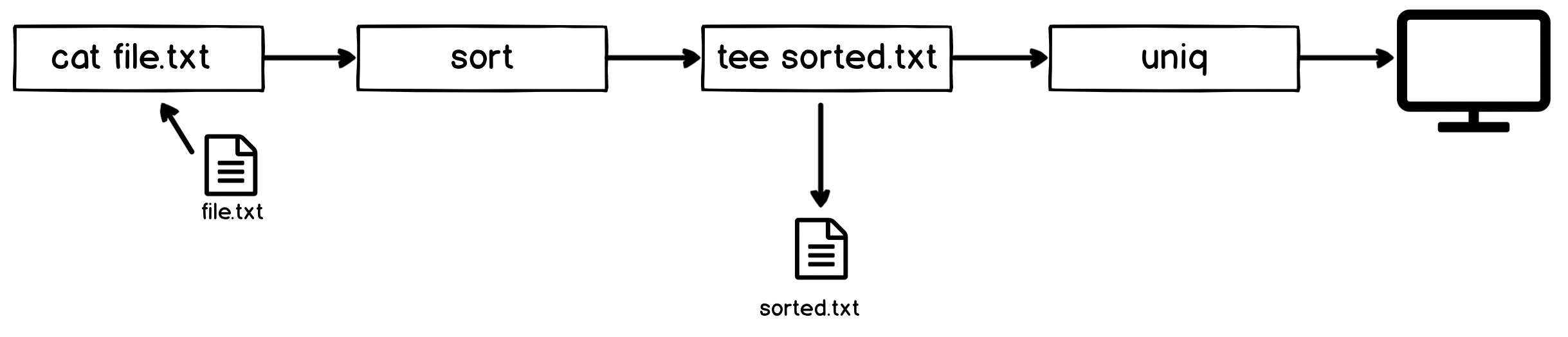
As soon as you visualise a T-pipe it's easy to remember this useful command! You might use it in more complex pipelines or other scenarios to write things to a file which would otherwise go straight to another program or just the display.
Thinking in Pipelines
Once you get comfortable with pipelines, a whole world of possibilities open up.
Just the day before I wrote this chapter, I had to find out how many unique data points were in a data file, which also included empty lines and comments, it took less than a minute to quickly build this:
cat data.dat | sort | uniq | grep -v '^#' | wc -l
I didn't have to find a special program which does exactly what I needed5 - I just incrementally built a pipeline. Each section I added one by one, writing to the screen each time, until I had it working. The thought process was:
cat data.dat- OK, first I need to write out the filesort- now I can sort it, that'll put all the blank lines togetheruniq- this'll remove all of those duplicate blank lines, although it still leaves one blank one at the top!grep -v '^#'- this should get rid of all the lines which start with#wc -l- this'll count the number of lines I'm left with
Now there's probably better ways, and this has an oddity which is that if there are blank lines it'll remove all but one of them (although that would be quick to fix), but it gave me my quick and dirty answer in less than a minute.
Of course, as things get more complex you might want to build scripts, or use a programming language, or other methods, but this Unix Philosophy (which we'll talk about more as we continue) of having lots of small, simple programs which we can chain together can be immensely powerful.
Summary
We'll see pipelines again and again. The standard streams, redirection, pipelines and all of the tricks we've introduced in this chapter are fundamental not only to using the shell effectively, but really understanding how computer programs work.
Don't be worried if this feels like a lot to take in - we'll see more and more examples in later chapters which will help reinforce these concepts. If you find yourself struggling later you might want to quickly review this chapter, because we introduced a lot!
In this chapter we looked at:
- How each program has access to three 'standard' streams - one for input, one for output and one for reporting errors
- The standard input stream is available as a file at
/dev/stdin, is often calledstdinin programming languages, and always has the special file descriptor0 - The standard output stream is available as a file at
/dev/stdout, is often calledstdoutin programming languages, and always has the special file descriptor1 - The standard error stream is available as a file at
/dev/stderr, is often calledstderrin programming languages, and always has the special file descriptor2 - The
Ctrl+Dsequence means 'end of transmission' - we can use it to signal that we have completed putting our input intostdin... - ...but the
Ctrl+Csequence means 'interrupt' and is normally used to force a program to close - We can pipe the output of one program to the input of another with the pipe
|symbol - We can redirect a file to the standard input of a program with the
<operator - We can redirect the standard output of a program to create or overwrite a file with the
>operator - We can redirect the standard output of a program to create or append to a file with the
>>operator - We can redirect the standard error of a program to its standard output with
2>&1 - We can redirect the standard error of a program to another file (such as the 'null' file) with
2>/dev/null - We can redirect the standard error of a program to create or append to a file, just like with standard output, using the
>>operator
We also briefly saw some commands:
sortsorts textsedcan replace content in texttrcan replace parts of textwccan count words or lines of textteetakes the input stream and sends it straight to the output, but also to a file (like a T-pipe in plumbing)grepcan filter lines
These programs can do a lot more and are workhorses we'll see in more detail through the book.
There are a few chapters which are planned to come later which go into detail on some of the concepts we only briefly touched on:
- Writing Good Programs - How to write programs which use
stdin,stdoutandstderrsensibly - The Unix Philosophy - Why we have so many small simple programs which we can pipe together
- Streams in Detail - How streams like
stdinactually work, especially with things like line endings, command sequences like^Dand so on - Signals - A little more on Signals (such as
^Cand^D)
When these chapters are published I'll update the links here. If you want to be updated when new chapters are published, you can Join the Mailing Lits on the Homepage.
- Technically there is another layer here, which is the
tty. You can see this by runningttyin the shell. We'll talk more about this in the Interlude - What is a Shell section.↩ - Check Chapter 4 - Becoming a Clipboard Gymnast for how to do this on a Linux or Windows machine.↩
- Although always use tricks like this with caution! If we had a different error, perhaps one we really do want to know about, we would lose the message in this case.↩
- There is a very detailed explanation of this behaviour at https://linuxnewbieguide.org/21-and-understanding-other-shell-scripts-idioms/.↩
- With the correct options,
sedcould likely do this in a single operation, but I'd probably spend a lot longer Googling the right options for it!↩