Controlling Changes with Git
Git is an extremely popular version control tool. You can use Git to track changes to text, code, or any type of files you might be working with. Many popular projects use Git as a tool to manage changes, allow others to contribute and collaborate, and to publish their projects.
In this chapter we'll look at the most common operations for Git to allow us to quickly and easily work with Git repositories. We'll learn Git on the command line by taking our 'dotfiles' folder (a simple set of shell configuration files) and showing how we can track and manage changes.
Being able to use Git from the command line is essential to being an effective shell user. In this chapter we'll look at setting up a local Git repository - in the next chapter we'll see how to share it online with the popular GitHub website.
What is Git
Any files or folders that we work with over time, such as our 'dotfiles' (i.e. our personal configuration files) will change. Sometimes new files get added, old files get deleted, files get changed, things get moved around and so on.
Git is a version control system that allows you to track changes to files and folders. This means that you can maintain a history of all of the changes that have been made, when they were made, who made them and why. You can also maintain multiple 'branches' of your files and folders - these branches can be used as working environments where you can make changes, without affecting the current 'main' set of files.
Git was written by Linus Torvalds (the creator of Linux) in 2006. "Git" is slang for an annoying person - Linus joked that he always names projects after himself, first Linux and now Git. There were many version control systems around before Git, such as CVS (Concurrent Version System) and SVN (Subversion, an system similar to CVS but with some improvements). There were also a number of proprietary and commercial solutions.
In recent years Git has become without a doubt the most popular version control system globally, and many highly popular software collaboration systems such as GitHub, GitLab and BitBucket use Git as their underlying version control system, adding additional features on top.
Creating a Git Repository
All of the information about a set of files or folders that you are tracking the changes for is stored in a Git repository. We can create a Git repository by running the git init (initialise Git repository) command.
Let's see this in action be creating a Git repository to track changes to our 'dotfiles' folder. Our 'dotfiles' folder is a folder where we keep simple shell configuration - you can read about how to create a folder like this in Chapter 27 - Managing Your Dotfiles or you can download the Effective Shell samples to get a copy of the 'dotfiles' folder.
Run the following command in your shell to download the samples:
curl effective.sh | sh
If you have installed the samples, you can copy the ~/effective-shell/dotfiles folder to your home directory - this is where we will create our Git repository and start using the Git commands:
$ cp -r ~/effective-shell/dotfiles ~/dotfiles
$ cd ~/dotfiles
We have created the ~/dotfiles folder in our home directory from the samples and moved into it.
Now we will initialise a Git repository with the git init command, and choose a 'branch' name with the git checkout command:
$ git init
Initialized empty Git repository in /home/dwmkerr/dotfiles/.git/
$ git checkout -b main
We'll see the git checkout command in detail soon. For now it is enough to know that we have initialised a new Git repository and chosen the name of our 'main' branch.
If you are using Git 2.2 or later, you can initialise a repository and set the branch name with a single command:
$ git init -b main
If you see the error message error: unknown switch 'b' then this means that you are using a version of Git that does not have the -b (initial branch name) flag (any version of Git lower than 2.2).
Adding and Resetting Changes to the Index
We now have an empty Git repository. We can use the git status (show the working tree status) command to show some information on the files in the working tree. The working tree is the folder that we are using Git to track changes for, in our case ~/dotfiles:
$ git status
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
install.sh
shell.d/
shell.sh
nothing added to commit but untracked files present (use "git add" to track)
The first thing that git status tells us is the name of the branch we are on. We'll look at branches in detail shortly. The next thing we see is that there are no commits - commits are sets of changes that we track. Finally, git is telling us that there are three files that are 'untracked'. These are the install.sh and shell.sh files as well as the shell.d folder.
If we are going to use Git to track changes to these files, we need to add them to the repository. We can do that with the git add (add file contents to index) command:
$ git add .
The git add command takes a list of file paths. We have used the special dot folder to represent the entire current directory. Let's take a look at the status again:
$ git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: install.sh
new file: shell.d/set_ps1.sh
new file: shell.sh
Git is now telling us that we have three new files which are ready to be committed. At the moment these files are in the index. The index, or staging area, is the set of changes that we are preparing to commit. These changes are not yet stored in the repository. When we add files to the index we are 'staging' changes. When we remove changes from the index, we are 'unstaging' changes.
Think of the index as a working area where we can build up a set of changes that we would later like to record in the repository. We could add more files to the index before we actually save them to the repository in a commit.
If we were to visualise what we've done so far, it would look like this:
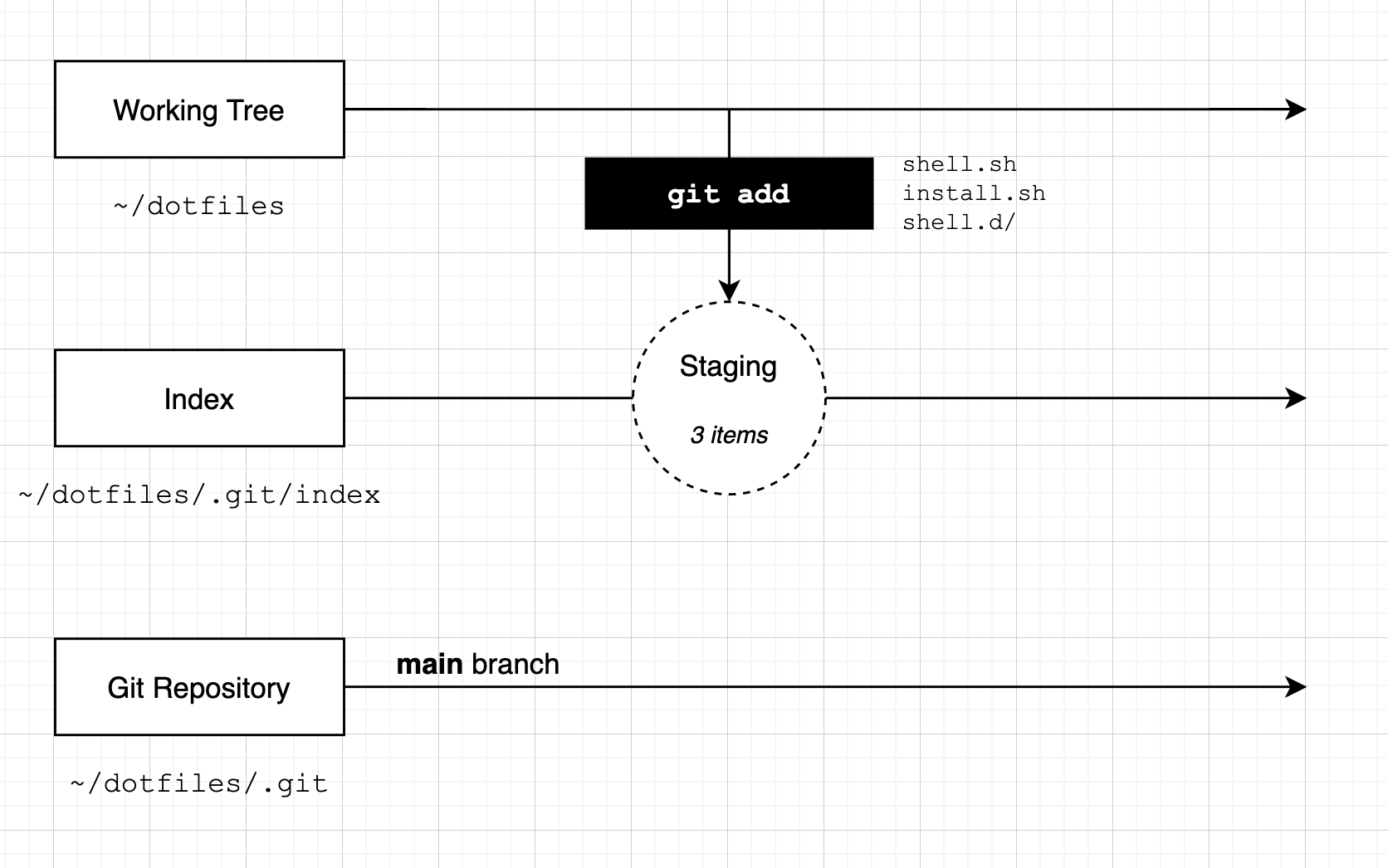
Our working tree is the folder associated with our Git repository, this is the ~/dotfiles folder. Our index is initially empty. When we run the git add command, we have told Git we want to add three files to the repository. Our 'staging area' has three files in it. Our Git repository does not have any commits recorded yet.
What if we realised that we don't want to add one of these files to the repository? To remove a file from the index we can use the git reset (reset changes) command. Let's reset the ~/dotfiles/shell.d/set_ps1.sh file and check the status:
$ git reset shell.d/set_ps1.sh
$ git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: install.sh
new file: shell.sh
Untracked files:
(use "git add <file>..." to include in what will be committed)
shell.d/
The git reset command has removed a change from the index - telling Git that we don't want to 'stage' one of the files. Git now tells us there are two files in the index and one that is not tracked.
Here's how we can visualise the changes we've made:
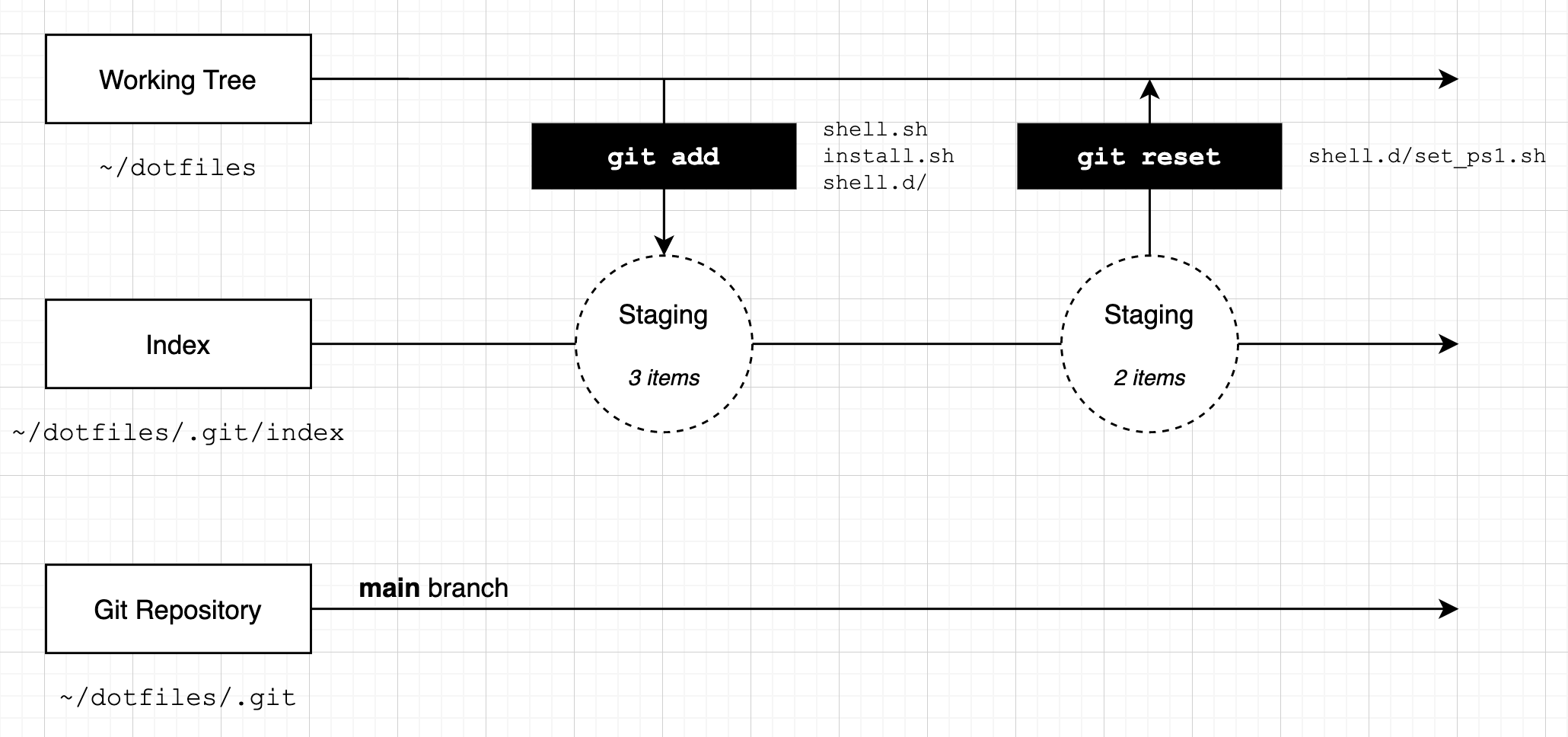
You can also reset changes by using the git rm --cached (remove changes from index) command. However, I think this is a little harder to work with as you have to remember to use the --cached flag to tell Git that you are removing from the index and not the repository. We'll see the git rm command a little later in the chapter.
Remember - at this stage we have not changed a single file! Nothing we have done has changed the content of any of the files in the working tree, and the only thing that has changed in the Git repository is the 'index' - the current set of files that we are 'staging'.
Now let's look at how we can commit our changes with the git commit command.
Committing Changes
Once we are happy with the set of changes in the index, we can use the git commit (record changes to the repository) command.
Now run the git commit command:
$ git commit
At this stage your shell editor will open up, with the text shown below:
# Please enter the commit message for your changes. Lines staring
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch main
#
# Initial commit
#
# Changes to be committed:
# new file: install.sh
# new file: shell.sh
#
# Untracked files:
# shell.d/
#
The reason you shell editor opens is that the git commit command would like you to provide a message describing your changes. Type a short description, such as:
add the 'install' and 'shell' scripts
# Please enter the commit message for your changes. Lines staring
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch main
#
# Initial commit
#
# Changes to be committed:
# new file: install.sh
# new file: shell.sh
#
# Untracked files:
# shell.d/
#
Note that below the cursor there is some information that starts with the # hash symbol. This is provided as a convenience - Git is telling you the status of the index. Anything that starts with a hash symbol is a comment and will not be stored in the commit message.
Save the file by pressing Ctrl+W and close the editor with Ctrl+X (these are the commands for the nano editor, if you are using a different editor use whatever commands are needed to save and close).
When the editor closes you'll see a confirmation below the git commit command:
$ git commit
[main (root-commit) 01e7a10] add the 'install' and 'shell' scripts
2 files changed, 90 insertions(+)
create mode 100755 install.sh
create mode 100644 shell.sh
This message tells us that two files have changed and 90 lines have been added. It also lists the files we have added. At this point we have created our first commit. We can visualise the process we have gone through like this:
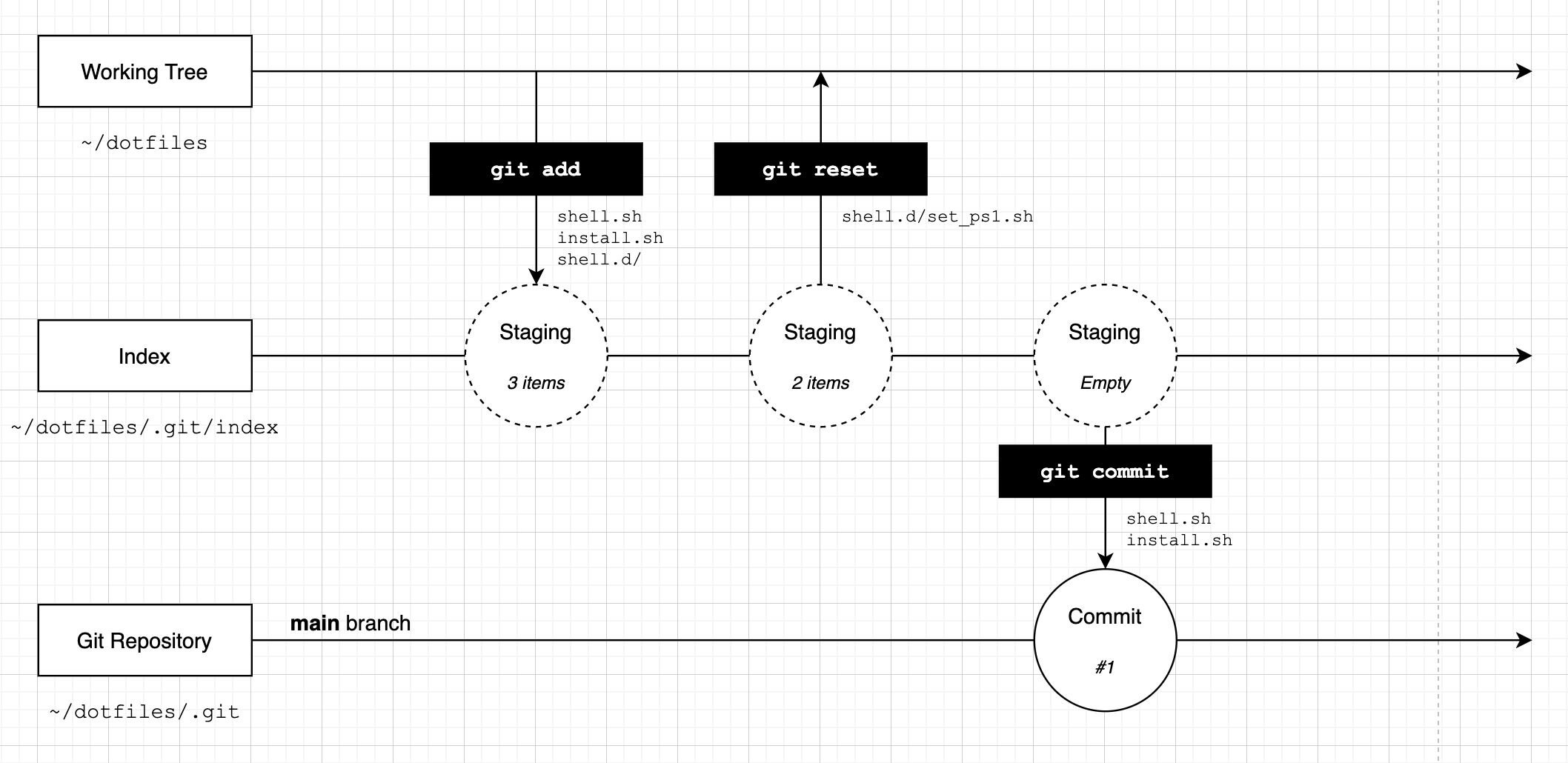
We 'staged' a set of changes and then 'committed' these changes. We now have a single commit in our repository. Our files are still unchanged, but our Git repository now has a single commit in it that tracks the two files we added.
Let's run git status again:
$ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
shell.d/
nothing added to commit but untracked files present (use "git add" to track)
The git status command tells us we're still on the 'main' branch, and that there is one file which is not tracked. Let's create a second commit by adding this file. When you run the git commit command below, enter a message to describe the commit:
$ git add .
$ git commit
[main d7e1bb9] add the 'shell.d' folder
1 file changed, 228 insertions(+)
create mode 100644 shell.d/set_ps1.sh
We have now created a second commit - our timeline will look like this:
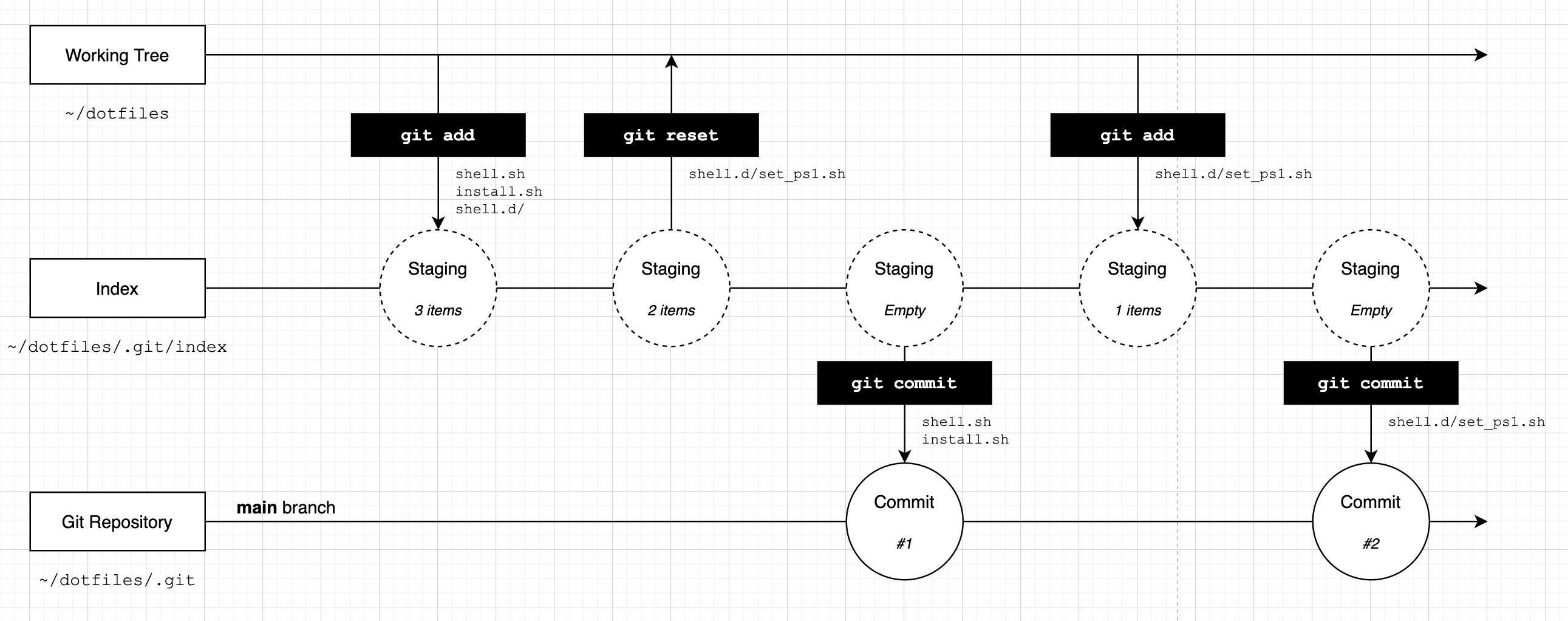
If we run the git status command one last time we will see that everything in the working tree is tracked in Git:
$ git status
On branch main
nothing to commit, working tree clean
The concepts of the 'index', the 'working tree' and the Git repository itself can take a bit of getting used to! If you have not used Git before and this seems like a lot to take on board, don't worry, people often find Git quite hard at first. As you use it more this will all become familiar and make more sense.
Commit Messages
You can use any text you like for a commit message. However, there are a couple of things that you should bear in mind:
- Try to keep the first line to 50 characters or less. This is known as the 'subject' line - keeping this short will make it easier to look through the log of changes later and see what each commit means.
- If you want to add more detail, leave a blank line after the subject line and then include as much text as you like. Common convention is to wrap the text at 80 characters so that it will fit in a typical shell window.
There are many articles available online that suggest conventions for how to write your commit messages. You can explore these as you get more familiar with Git. The only convention I would strongly recommend that you follow is to make sure that your Git message makes sense - it should describe what the change is and ideally why you have made it. It is easy to forget why changes were made after time has passed - writing good commit messages will save you a lot of time in the long run and also make it easier for others to work with your repository!
Now let's take a look at how we can work on changes to our files with branches.
Creating Branches
The commits that we have made so far have been on a 'branch' named 'main'. We can create new 'branches' and put commits on them to allow us to make a series of changes that are isolated from each other.
We can create branches using the git branch (list, create or delete branches) or git checkout (switch branches or restore working tree) command. To show these features in action, we'll create a new branch called aliases and add some files to it:
$ git checkout -b aliases
Switched to a new branch 'aliases'
$ git status
On branch aliases
nothing to commit, working tree clean
We have used the git checkout command to 'switch' to another branch. The -b (new branch) option tells Git that we want to create a new branch. The git status command now shows the new branch name when we run it.
Let's create a new file which includes an alias for the git status command, then let's see what git status tells us about the status of the working tree:
$ echo 'alias gs="git status"' >> ./shell.d/git_aliases.sh
$ git status
On branch aliases
Untracked files:
(use "git add <file>..." to include in what will be committed)
shell.d/git_aliases.sh
nothing added to commit but untracked files present (use "git add" to track)
Excellent - we have a new file and Git knows that it is not currently tracked. Let's stage this file and then commit it:
$ git add .
$ git commit -m "add alias 'gs' for 'git status'"
[aliases f61369d] add alias 'gs' for 'git status'
1 file changed, 1 insertion(+)
create mode 100644 shell.d/git_aliases.sh
In the example above I used the -m (commit message) parameter for the git commit command, this means my editor will not open up as we've already provided a commit message.
We now have a series of commits that looks like this:
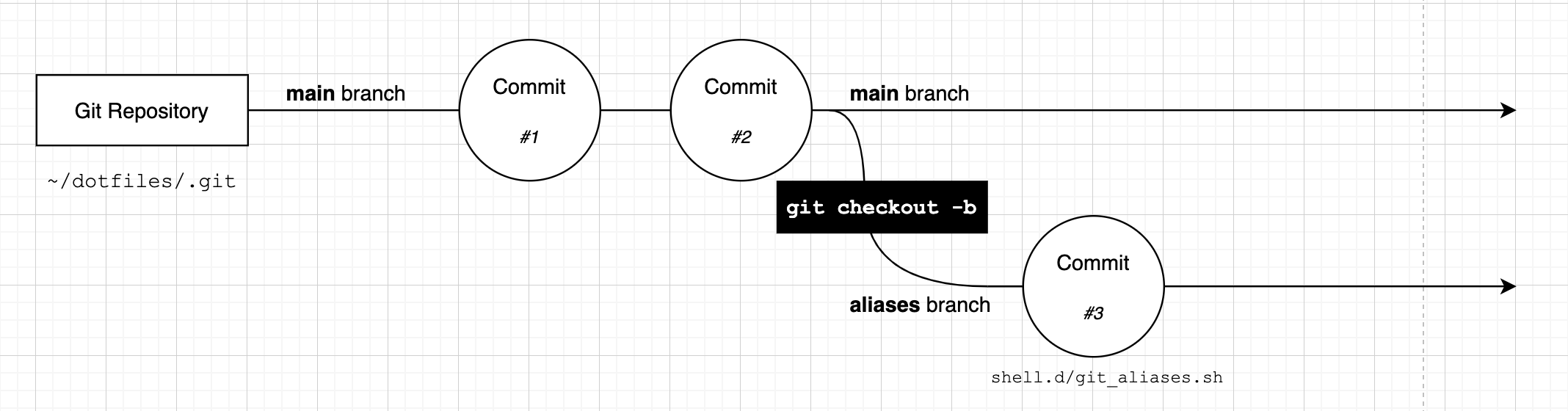
Our new ~/dotfiles/shell.d/git_aliases.sh file has been committed to the aliases branch.
We can switch back to the main branch at any time with git checkout:
$ git checkout main
Switched to branch 'main'
$ tree
.
├── install.sh
├── shell.d
│ └── set_ps1.sh
└── shell.sh
When we switch back to the main branch and look at our working tree we can see that the git_aliases.sh file is not present. This is very cool - by passing the name of the branch we want to switch to as the parameter to the git checkout command we can switch branches. If we are on the main branch we don't see the git_aliases.sh file, because the commit that added is was not on the main branch. To go back to the aliases branch we can just checkout again:
$ git checkout aliases
Switched to branch 'aliases'
$ tree
.
├── install.sh
├── shell.d
│ ├── git_aliases.sh
│ └── set_ps1.sh
└── shell.sh
As a nice little tip, you can always go back to the last branch you were on by running git checkout - just like you can use cd - to change to the last directory you visited! The dash character is a shortcut for the last branch you were on.
Let's add another alias to the file and create another commit:
$ echo 'alias gcm="git checkout main"' >> ./shell.d/git_aliases.sh
$ git add .
$ git commit -m "add alias 'gcm' for 'git checkout main'"
[aliases b9ae0ad] add alias 'gcm' for 'git checkout main'
1 file changed, 1 insertion(+)
Our branches will now look like this:
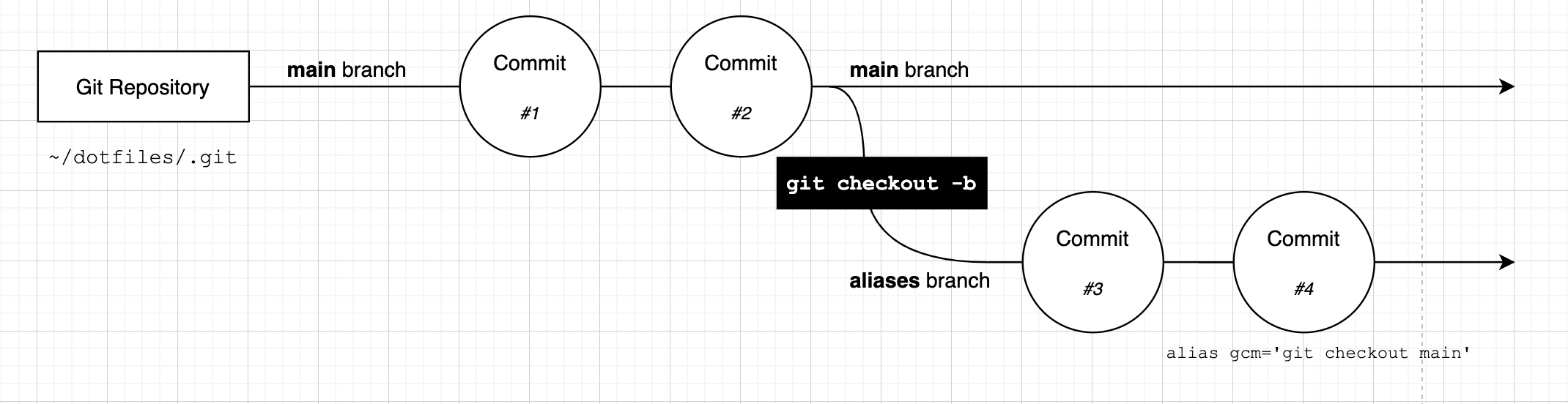
You can create as many branches as you like - just remember that when you run git checkout -b, you branch from the current branch (and in fact, the current HEAD, which we will see a little later).
If you want to create a branch, but don't want to switch to it, you can run git branch <new_branch_name>. This command will create a branch from your current position, but will not move to it.
Merging
You can use the git merge (join two or more branches) command to take the changes from one branch and bring them into another.
We can merge the changes from our aliases branch into the main branch of the repository by first checking out the branch we want to merge into, and then running git merge:
$ git checkout main
$ git merge aliases
Updating d7e1bb9..b9ae0ad
Fast-forward
shell.d/git_aliases.sh | 2 ++
1 file changed, 2 insertions(+)
create mode 100644 shell.d/git_aliases.sh
When we run the git merge command Git tells us what type of merge it has performed. In this case we have a fast forward merge, which is the most simple type of merge. When Git tries to merge the two branches, it sees that each of the commits on the aliases branch can be applied sequentially to the main branch:
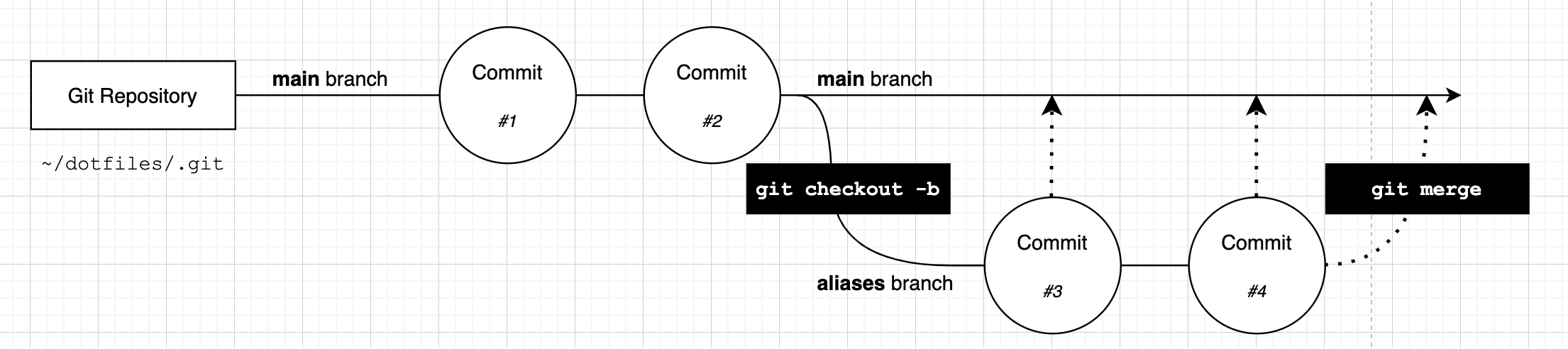
One the merge is complete, our branches look like this:

The main branch and aliases branch contain the exact same set of commits.
Let's look at a more common merge scenario - merging branches that have diverged.
Merging Diverged Branches
Let's create set of commits that show a case where we our branches have diverged - the branches both have their own new commits:
# Create a branch called 'more_aliases', add a file to it, then commit.
git checkout -b more_aliases
touch ./shell.d/bash_aliases.sh
git add .
git commit -m "add a file to store 'bash' aliases"
# Create another file, add it, then commit.
touch ./shell.d/zsh_aliases.sh
git add .
git commit -m "add a file to store 'zsh' aliases"
This snippet checks out a new branch called more_aliases and adds two new empty files, as two separate commits. Now we'll go back to our main branch and change a file:
# Go back to the 'main' branch, add and commit another file.
git checkout main
echo 'alias gm="git merge"' >> ./shell.d/git_aliases.sh
git commit -a -m "add the 'gm' alias for 'git merge'"
I have added a new alias to the shell.d/git_aliases.sh file. By adding the -a (all changes) flag to the git commit command I was able to add the changes to the index and commit them with a single command.
Our branches now look like this:
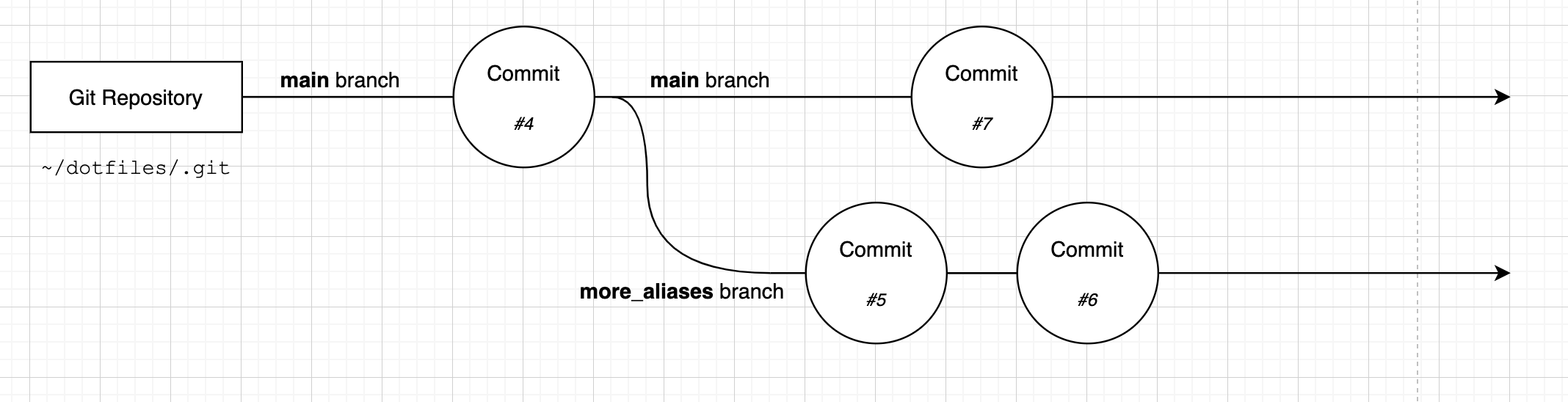
Let's merge the more_aliases branch into the main branch:
$ git merge more_aliases
At this point your shell editor will open up with a request for a commit message:
Merge branch 'more_aliases'
# Please enter a commit message to explain why this merge is needed
# especially if it merges an updated upstream into a topic branch.
#
# Lines starting with '#' will be ignored, and an empty message will abort
# the commit.
Git is going to create a new commit on the main branch that brings in the changes from the bash_aliases branch. Because a new commit is going to be created, Git asks us to provide a message. The default message simply explains that this commit merges the branch named more_aliases.
You can change the message or leave it as is. Save the file when you have entered the message and the output below will be shown:
$ git merge more_aliases
Merge made by the 'recursive' strategy.
shell.d/bash_aliases.sh | 0
shell.d/zsh_aliases.sh | 0
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 shell.d/bash_aliases.sh
create mode 100644 shell.d/zsh_aliases.sh
Git now tells us that we have made a recursive merge and our branches will look like this:
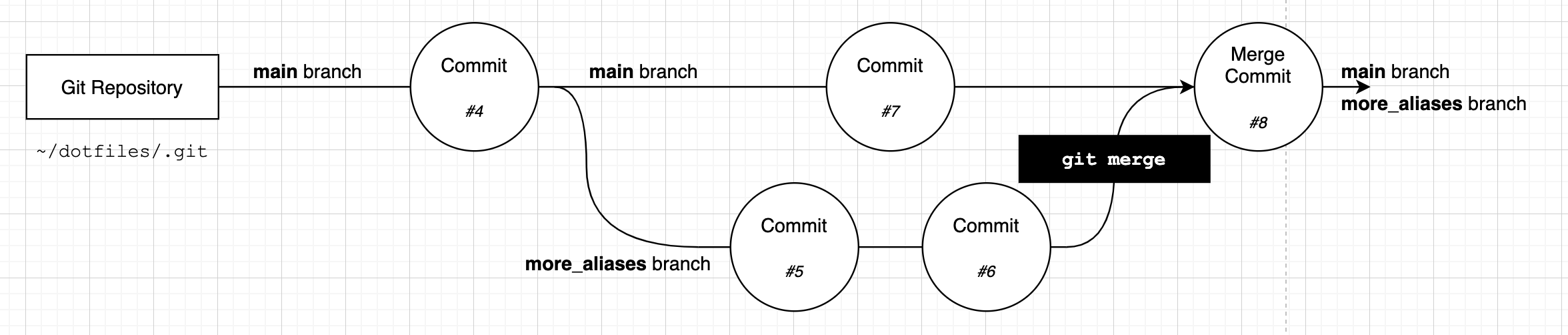
At this stage both the main branch and the more_aliases branch have the full set of changes that we made to both of the branches. Git merged the two branches together and created a new commit that joins them.
The Git Log
In the diagrams we've shown we've given each commit a number. This was just to make things easier to read - Git doesn't use a number for commits. Git uses a SHA, which is a hash. A hash is a sequence of letters and numbers that uniquely identify each commit.
You can use the git log (show commit logs) command to see the log of commits and their SHAs:
$ git log
commit 138b40418d5658bc64421e7bcf2680c8339f8350 (HEAD)
Merge: a95bd90 a51ae1a
Author: Dave Kerr <dwmkerr@gmail.com>
Date: Tue Jun 15 21:00:28 2021 +0800
Merge branch 'more_aliases'
commit a95bd90e3656b2e55b8708193d387c80c282a6ad
Author: Dave Kerr <dwmkerr@gmail.com>
Date: Tue Jun 15 21:00:22 2021 +0800
add the 'gm' alias for 'git merge'
commit a51ae1aa42432c2f391ca782c1c20b3793c232ab (more_aliases)
Author: Dave Kerr <dwmkerr@gmail.com>
Date: Tue Jun 15 20:53:01 2021 +0800
add a file to store 'zsh' aliases
You can see that the log shows each of the commits, the branch the commit was on, the message, the date and so on.
If you want to see a more compact log you can use the --oneline (show one line per commit) flag:
$ git log --oneline
138b404 (HEAD) Merge branch 'more_aliases'
a95bd90 add the 'gm' alias for 'git merge'
a51ae1a (more_aliases) add a file to store 'zsh' aliases
63ea74f add a file to store 'bash' aliases
b9ae0ad (aliases) add alias 'gcm' for 'git checkout main'
f61369d add alias 'gs' for 'git status'
d7e1bb9 add the 'shell.d' folder
01e7a10 add the 'install' and 'shell' scripts
When you run this command yourself it will be a little easier to read as the output uses different colours for the SHAs and the branch names.
We can even see a 'graph' view, showing the branches we have made and when they branched off and were merged back. To do this, pass the --graph (show commit graph) flag:
$ git log --oneline --graph
* 138b404 (HEAD) Merge branch 'more_aliases'
| \
| * a51ae1a (more_aliases) add a file to store 'zsh' aliases
| * 63ea74f add a file to store 'bash' aliases
* | a95bd90 add the 'gm' alias for 'git merge'
|/
* b9ae0ad (aliases) add alias 'gcm' for 'git checkout main'
* f61369d add alias 'gs' for 'git status'
* d7e1bb9 add the 'shell.d' folder
* 01e7a10 add the 'install' and 'shell' scripts
Each commit is shown with an * asterisk symbol - we can also see when we created the more_aliases branch and when we merged it back in.
The Git log is very useful to help you understand the changes that have happened in the repository.
Merge Conflicts
One of the most important features of any version control system is the ability to manage conflicts. Conflicts occur when a set of changes are made that cannot be merged without some kind of manual intervention to decide which of the changes are correct.
Here are a few common scenarios that might lead to merge conflicts:
- In one branch a file is deleted and in another branch the file is changed - when we merge should we delete the file or keep the version with the changes?
- In one branch a file is edited and in another branch the same part of the file is edited in a different way - which edit should we keep? Should we keep both?
- In one branch we add content to the end of a file and in another branch we add different content - which of these changes should come first?
A lot of the time you can avoid conflicts by making sure that you don't keep branches for too long - if other people are merging changes into the main branch while you are working on another branch, you are drifting from the main branch. You should either regularly update your branch with the changes in main or merge your changes into main.
There are many different ways for version control systems to manage conflicts. Let's see how Git does it by creating a conflict.
First, we will create a branch that adds a new alias to the git_aliases.sh file:
# Create a 'glog_alias' branch and commit a file.
git checkout -b glog_alias
echo 'alias glog="git log --graph --oneline"' >> ./shell.d/git_aliases.sh
git commit -a -m "add the 'glog' alias"
Now we'll go back to the main branch and add another alias:
# Go back to 'main' and commit a change to the same file as the last one.
git checkout main
echo 'alias glog="git log"' >> ./shell.d/git_aliases.sh
git commit -a -m "add the 'glog' alias"
We've changed the same file in two branches - if we try to merge we will get a conflict:
$ git merge glog_alias
Auto-merging shell.d/git_aliases.sh
CONFLICT (content): Merge conflict in shell.d/git_aliases.sh
Automatic merge failed; fix conflicts and then commit the result.
When Git cannot automatically consolidate the changes into a single merge commit, it aborts the merge process. No new commits have been made - the conflicted files with their changes are in the index. We have to now manually fix these files.
Let's see what the status shows:
$ git status
On branch main
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: shell.d/git_aliases.sh
no changes added to commit (use "git add" and/or "git commit -a")
Git is telling us that we are currently in the process of trying to fix a merge conflict. It is telling us that we need to fix the shell.d/git_aliases.sh file, then use git add to stage the changes and commit the result.
To resolve the conflict, we need to edit the file. If you open the file in an editor it will look like this:
alias gs="git status"
alias gcm="git checkout main"
alias gm="git merge"
<<<<<<< HEAD
alias glog="git log"
=======
alias glog="git log --graph --oneline"
>>>>>>> glog_alias
Many modern editors will immediately recognise the sequence of symbols that Git uses to indicate conflicts and highlight them. The <<<<<< HEAD line indicates the changes in the current branch, the ======= line is a separator, and the >>>>>> glog_alias line indicates that everything since the ======= line is the changes in the glog_alias branch.
We can see why Git has not been able to merge these changes - each branch has a new line and Git doesn't know which one is correct. So rather than make an assumption (such as the most recent change should 'win'), Git is asking us to choose.
In your editor, update the file to look like this:
alias gs="git status"
alias gcm="git checkout main"
alias gm="git merge"
alias glog="git log --graph --oneline"
We have chosen the version of the glog alias that was in the glog_alias branch. But you could choose either - or replace the content with a new line. You can make any changes you like - just be sure to remove the lines that start with <<<, === and >>>. We don't even have to use the changes from one of the branches - we could remove the lines or add completely new ones. We change the file to make sure that the merged result makes sense.
In the example above we deleted one of the glog aliases, but we could have also just changed the name of one of them:
alias gs="git status"
alias gcm="git checkout main"
alias gm="git merge"
alias glog="git log"
alias ggraph="git log --graph --oneline"
We can now use git add to mark the file as resolved, and run git commit:
$ git add shell.d/git_aliases.sh
The editor will open showing a sensible commit message:
Merge branch 'glog_alias'
# Conflicts:
# shell.d/git_aliases.sh
#
# It looks like you may be committing a merge.
# If this is not correct, please run
# git update-ref -d MERGE_HEAD
# and try again.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# On branch main
The message is just like the earlier merge commit message, but the comments show a little more information (the files that were conflicted). Save the file and close the editor to complete the commit.
Our Git log will now show this new merge commit:
$ git log --graph --oneline
* 2532277 (HEAD -> main) Merge branch 'glog_alias'
|\
| * a8cbb15 (glog_alias) add the 'glog' alias
* | 31548e4 add the 'glog' alias
|/
* 138b404 Merge branch 'more_aliases'
|\
| * a51ae1a (more_aliases) add a file to store 'zsh' aliases
| * 63ea74f add a file to store 'bash' aliases
* | a95bd90 add the 'gm' alias for 'git merge'
|/
* b9ae0ad (aliases) add alias 'gcm' for 'git checkout main'
* f61369d add alias 'gs' for 'git status'
* d7e1bb9 add the 'shell.d' folder
* 01e7a10 add the 'install' and 'shell' scripts
Dealing with conflicts can be extremely complicated. We have only scratched the surface here, but there is a wealth of information online if you'd like to go deeper.
Other Merge Strategies
Git has a number of merge strategies that can be used to combine the changes across branches. Going into them is beyond the scope of this book. However, it is useful to know that you have a lot of functionality to control how branches are merged available to you if you want to explore further.
There are merge strategies that allow you to try and create a single, coherent history between two branches, rather than creating a merge commit, there are options to 'squash' all of the commits from one branch into another and more.
I would suggest that as you become more familiar with the basics of how Git works, you get a little deeper on this topic - searching online for "Git Merge Strategies" will bring up many articles going into detail.
Deleting and Renaming Files
It is quite simple to remove files from your Git Repository. You can either ask Git to remove the file for you, or just delete the file yourself and then tell Git that you have removed it.
Let's see both ways in action. First we'll use the git rm (remove files from the working tree and index) command:
$ git rm install.sh
rm 'install.sh'
The git rm command removes the file from your working tree and stages the deletion. We can see that the file is staged for deletion if we run git status:
$ git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
deleted: install.sh
The deletion is only in the index at this stage - we need to run git commit to commit the deletion.
If we want to restore the file, we can use git checkout to get the file back from Git:
$ git checkout HEAD install.sh
We use HEAD to tell Git what commit we want to checkout the file from - head means the current commit we are on (which is the most recent commit on main).
Another common way to delete a file is to simply remove it from the file-system:
$ rm install.sh
$ git status
On branch main
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted: install.sh
At this point Git knows the file is missing, but the deletion is not yet staged - because we haven't explicitly told Git that we want to remove this file as part of the commit we are creating. To confirm that we want to remove the file we can use:
$ git rm install.sh
We could also run git add install.sh - think of this like saying 'stage my change to index.sh' - we are adding a change to the index. I often just run git add . to add all of my changes (including deletions) to the stage. At this point we can make any other changes we like, stage them, and then commit.
Let's restore the file:
$ git reset .
Unstaged changes after reset:
D install.sh
$ git checkout .
Updated 1 path from the index
This is another way to restore the file - first we reset all of the changes to the index with git reset ., then we checkout all of the files in the current commit with git checkout .. But be careful with this method - it will also reset any other changes you have made. I prefer the git checkout HEAD <file_path> method as it is more explicit and only restores one file.
What about if we rename a file? Let's rename the install file and see what the status is:
$ mv install.sh install_dotfiles.sh
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted: install.sh
Untracked files:
(use "git add <file>..." to include in what will be committed)
install_dotfiles.sh
no changes added to commit (use "git add" and/or "git commit -a")
We've renamed the file, but when we run git status it is telling us that the file is missing, and there is a new untracked file. But Git is smart enough to know when we move a file - if we run git add . to add all changes in the working tree to the index, Git will recognise that we have not deleted and added a file, but instead renamed it:
$ git add .
$ git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
renamed: install.sh -> install_dotfiles.sh
Let's restore the file by renaming it back to what it was and adding these changes:
$ mv install_dotfiles.sh install.sh
$ git add .
$ git status
On branch main
nothing to commit, working tree clean
We can also use the git mv (move or rename a file) command to move or rename a file and stage the changes in one go:
$ git mv install.sh install_dotfiles.sh
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
renamed: install.sh -> install_dotfiles.sh
We can also restore the changes by using git mv:
$ git mv install_dotfiles.sh install.sh
$ git status
On branch main
nothing to commit, working tree clean
These commands work equally well with folders, or lists of files and folders.
Restoring Your Working Tree
We've already seen how the git checkout command can be used to switch branches. We can also use the git checkout command to restore our working tree to a certain point in our commit history. This is extremely useful if you want to see how your files looked at an earlier point in time, or restore your files to a previous state.
Let's take a quick look at our Git log so far.
$ git log --graph --oneline
* 2532277 (HEAD -> main) Merge branch 'glog_alias'
|\
| * a8cbb15 (glog_alias) add the 'glog' alias
* | 31548e4 add the 'glog' alias
|/
* 138b404 Merge branch 'more_aliases'
|\
| * a51ae1a (more_aliases) add a file to store 'zsh' aliases
| * 63ea74f add a file to store 'bash' aliases
* | a95bd90 add the 'gm' alias for 'git merge'
|/
* b9ae0ad (aliases) add alias 'gcm' for 'git checkout main'
* f61369d add alias 'gs' for 'git status'
* d7e1bb9 add the 'shell.d' folder
* 01e7a10 add the 'install' and 'shell' scripts
The Git log is showing the first seven digits of the SHA for each commit. We can checkout any commit by providing its SHA. We don't need to provide the entire SHA (which is good, because they are normally quite long), we only need to provide enough letters to uniquely identify the commit, so normally four or five digits is plenty.
Notice that the most recent commit is marked with the text HEAD. The HEAD is where Git is currently 'pointing' to - we will see how to move the head shortly (the term HEAD also refers to the most recent commit of a branch).
At the moment we can visualise our Git log, with the commits, branches and HEAD like so:
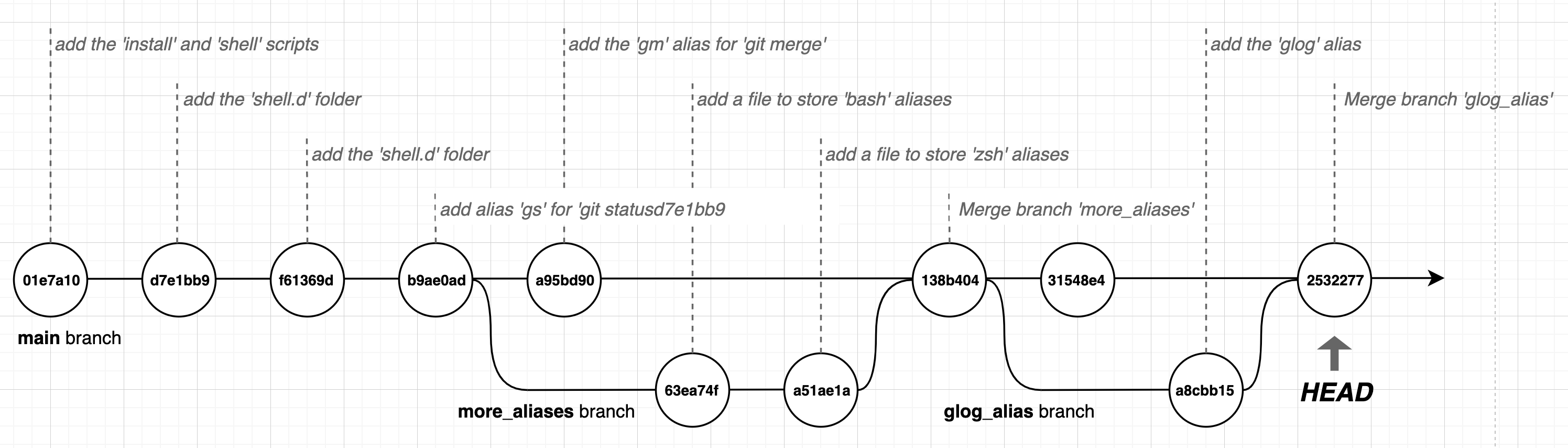
We can restore the working tree to the state of any of the commits by running git checkout <commit_sha>:
$ git checkout f61369d
Note: switching to 'f61369d'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
This snippet moved our HEAD to the third commit in our repository. If you look at the files in your working tree you'll see that they are in exact state that they were when we made our third commit. Visually, we have moved the HEAD as shown below:
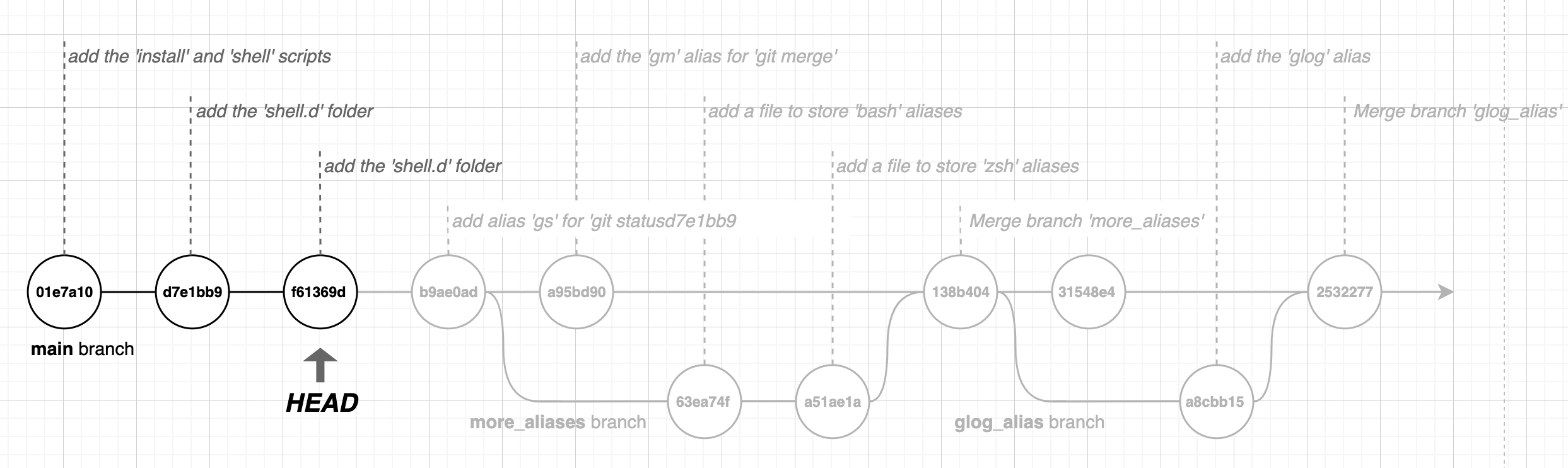
The warning that says we are in a 'detached HEAD' state is telling us that our current position in the history is not at the 'tip' of a branch - this means we cannot create a new commit without first starting a new branch.
If we want to move back to the 'tip' of our main branch (or any other branch), we can use git checkout <branch_name>:
$ git checkout main
This moves us back to the 'tip' of the main branch.
Git has a very convenient syntax we can use to move backwards. We can specify a branch name, a SHA or 'HEAD', use a ~ tilde character, and then provide the number of commits we want to move 'backwards':
$ git checkout HEAD~1
This command moves the 'head' backwards one commit. This is useful if you realise you have made a mistake with your commit or recent commits and want to go backwards.
Remember - whenever you run git checkout <branch_name> Git moves the HEAD to the tip of the branch by default.
Summary
In this chapter we looked at some of the core concepts behind Git - the repository, the working tree and the index. We saw how to stage and unstage changes, commit changes, create branches, merge branches, deal with conflicts and remove and rename files.
In the next chapter we will look at how to work with 'remote' repositories - this will allow us to push our changes up to a location on the internet and share these changes with other users, or to download these changes to other machines we might work on.
We've introduced a lot of commands in this chapter - you can use this table as a quick reference:
| Command | Description |
|---|---|
git init | Initialise a new Git Repository. |
git status | Show the status of the working tree and index. |
git add <files> | Stage files - you can use patterns and wildcards. |
git reset <files> | Unstage files - you can use patterns and wildcards. |
git rm --cached <files> | Unstage files - you can use patterns and wildcards. |
git commit | Create a commit from the current index - the shell editor will open for the commit message. |
git commit -m 'message' | Create a commit with message message. |
git commit -a | Stage and commit all changes in the working tree. |
git checkout <branch> | Checkout a branch called branch. |
git checkout -b branch | Create and checkout a new branch called branch. |
git branch <name> | Create a branch called name but do not check it out. |
git branch -m <new_name> | Change the current branch name to new_name. |
git merge <branch> | Merge the branch named branch into the current branch. |
git log | Show the log of commits. |
git log --oneline --branch | Show the log of commits, one line per commit, with the branch graph. |
git rm <files> | Stage the removal of files from the repostiry - you can use patterns and wildcards. |
git mv <source> <destination> | Stage the movement of source to destination. |
git checkout 8342bec | Checkout a commit with SHA 834bec. |
git checkout HEAD~1 | Move the current HEAD back one commit. |
git checkout <branch>~3 | Checkout branch, move back three commits from the tip. |